I. ĐỊNH NGHĨA VÀ PHÂN LOẠI ĐẠI LƯỢNG NGẪU NHIÊN
1) Định nghĩa: Đại lượng ngẫu nhiên là đại lượng mà trong kết quả của phép thử sẽ nhận một và chỉ một trong các giá trị có thể có của nó với một xác suất tương ứng xác định.
Các đại lượng ngẫu nhiên thường được ký hiệu bằng chữ cái lớn ở cuối bảng chữ cái: X, Y, Z hoặc X1, X2, …, Xn; Y1, Y2, …, Yn và dùng các chữ nhỏ để ký hiệu các giá trị có thể có (giá trị cụ thể) của chúng. Chẳng hạn X nhận các giá trị x1, x2, …, xn.
Ta chú ý rằng sở dĩ đại lượng X nào đó gọi là ngẫu nhiên vì trước khi tiến hành phép thử ta chưa có thể nói một cách chắc chắn nó sẽ nhận giá trị bằng bao nhiêu mà chỉ có thể dự đoán điều đó với một xác suất nhất định.
Nói một cách khác ,việc X nhận giá trị nào đó (X = x1) hay (X = x2), …, (X = xn) về thực chất là các biến cố ngẫu nhiên. Hơn nữa vì trong kết quả của phép thử đại lượng X nhất định sẽ nhận một và chỉ một trong các giá trị có thể có của nó, do đó các biến cố (X = x1), (X = x2), …, (X = xn) tạo nên một nhóm biến cố đầy đủ.
Thí dụ 1: Tung một con xúc xắc. Gọi X là “số chấm xuất hiện” thì X là đại lượng ngẫu nhiên vì trong kết quả của phép thử nó sẽ nhận một trong 6 giá trị: 1, 2, 3, 4, 5, 6 với xác suất tương ứng đều bằng 1/6.
Thí dụ 2: Gọi Y là số phế phẩm có trong 50 sản phẩm lấy ra kiểm tra. Y là đại lượng ngẫu nhiên vì trong kết quả của phép thử Y sẽ nhận một trong các giá trị 0, 1, 2, …, 50.
2) Phân loại đại lượng ngẫu nhiên
Trong số các đại lượng ngẫu nhiên thường gặp trong thực tế có thể phân thành hai loại chủ yếu: đại lượng ngẫu nhiên rời rạc và đại lượng ngẫu nhiên liên tục.
* Đại lượng ngẫu nhiên được gọi là rời rạc nếu các giá trị có thể có của nó lập nên một tập hợp hữu hạn hoặc đếm được.
Nói cách khác đại lượng ngẫu nhiên sẽ là rời rạc nếu ta có thể liệt kê được tất cả các giá trị có thể có của nó.
* Đại lượng ngẫu nhiên được gọi là liên tục nếu các giá trị có thể có của nó lấp kín một khoảng trên trục số.
Đối với đại lượng ngẫu nhiên liên tục ta không thể liệt kê được các giá trị có thể có của nó.
Thí dụ 3: một phân xưởng có 4 máy hoạt động. Gọi X là: “số máy hỏng trong một ca”. X là đại lượng ngẫu nhiên rời rạc với các giá trị có thể có là X = 0, 1, 2, 3, 4.
Thí dụ 4: Gọi X là “kích thước của chi tiết do một máy sản xuất ra”, X là đại lượng ngẫu nhiên liên tục.
II. QUY LUẬT PHÂN PHỐI XÁC SUẤT CỦA ĐẠI LƯỢNG NGẪU NHIÊN
Để xác định một đại lượng ngẫu nhiên, trước hết ta phải biết đại lượng ngẫu nhiên ấy có thể nhận các giá trị nào. Nhưng mặt khác ta phải biết nó nhận các giá trị trên với xác suất tương ứng là bao nhiêu.
Bất kỳ một hình thức nào cho phép biểu diễn mối quan hệ giữa các giá trị có thể có của đại lượng ngẫu nhiên và các xác suất tương ứng đều được gọi là quy luật phân phối xác suất của đại lượng ngẫu nhiên ấy.
Để thiết lập quy luật phân phối xác suất của một đại lượng ngẫu nhiên ta có thể dùng: bảng phân phối xác suất, hàm phân phối xác suất và hàm mật độ xác suất.
1. Bảng phân phối xác suất:
Bảng phân phối xác suất dùng để thiết lập quy luật phân phối xác suất của đại lượng ngẫu nhiên rời rạc.
Giả sử đại lượng ngẫu nhiên rời rạc X có thể nhận một trong các giá trị có thể có là x1, x2, …, xn với các xác suất tương ứng là p1, p2, …, pn. Bảng phân phối xác suất của X có dạng:

Trong đó các xác suất pi (i = 1, 2, …, n) phải thoả mãn các điều kiện:


Điều kiện thứ nhất là hiển nhiên vì theo tính chất của xác suất, còn điều kiện thứ hai là do các biến cố (X = x1), (X =x2), …, (X = xn) tạo nên một nhóm biến cố đầy đủ, nên tổng xác suất của chúng bằng một.
Thí dụ 1: Tung một con xúc xắc. Gọi X là “số chấm xuất hiện”. Bảng phân phối xác suất X có dạng:

Thí dụ 2: Trong hộp có 10 sản phẩm trong đó có 6 chính phẩm. lấy ngẫu nhiên 2 sản phẩm, xây dựng quy luật phân phối xác suất của số chính phẩm được lấy ra.
Giải: Gọi X là: “số chính phẩm được lấy ra từ hộp” thì X là đại lượng ngẫu nhiên rời rạc có thể nhận các giá trị 0, 1, 2 với các xác suất tương ứng:
 = \dfrac{{C_4^2 }}{{C_{10}^2 }} = \dfrac{2}{{15}}")
 = \dfrac{{C_6^1 C_4^1 }}{{C_{10}^2 }} = \dfrac{8}{{15}}")
 = \dfrac{{C_6^2 }}{{C_{10}^2 }} = \dfrac{5}{{15}}")
Vậy quy luật phân phối xác suất của X là:

2. Hàm phân phối xác suất:
Hàm phân phối xác suất áp dụng cho cả đại lượng ngẫu nhiên rời rạc và liên tục.
Giả sử X là đại lượng ngẫu nhiên bất kỳ, x là một số thực nào đó. Xét biến cố “đại lượng ngẫu nhiên X nhận giá trị nhỏ hơn x”. Biến cố này được ký hiệu (X < x). Hiển nhiên là x thay đổi thì xác suất P(X < x) cũng thay đổi theo. Như vậy xác suất này là một hàm số của x.
a) Định nghĩa: Hàm phân phối xác suất của đại lượng ngẫu nhiên X, ký hiệu là F(x) là xác suất để đại lượng ngẫu nhiên nhận giá trị nhỏ hơn x, với x là một số thực bất kỳ.
 = P(X < x)")
Ta chú ý rằng đây là định nghĩa tổng quát của hàm phân phối xác suất. Đối với từng loại đại lượng ngẫu nhiên hàm phân phối xác suất được tính theo công thức riêng. Chẳng hạn nếu X là đại lượng ngẫu nhiên rời rạc thì hàm phân phối xác suất F(x) được xác định bằng công thức
 = \sum\limits_{x_i < x} {P_i }") (1)
(1)(Trong đó ký hiệu xi < x dưới dấu Σ có nghĩa là tổng này được lấy theo mọi trị số xi của đại lượng ngẫu nhiên bé hơn x).
Thí dụ: Tiến hành bắn 3 viên đạn độc lập. Xác suất trúng bia của mỗi viên bằng 0,4. Lập hàm phân phối của số lần trúng.
Giải: Gọi X là số lần trúng. X có thể nhận các giá trị: 0, 1, 2, 3. Với các xác suất tương ứng là:
 = (0,6)^3 = 0,216")
 = C_{1}^{3}. 0,4.(0,6)^2 = 0,432")
 = C_2^3.(0,4)^2. 0,6 = 0,288")
 = (0,4)^3 = 0,064")
Ta có bảng phân phối xác suất của X:

* Khi x = 0, biến cố (X < x) là biến cố không thể có do đó F(x) = 0
* Khi 0 < x = 1 biến cố (X < x) chỉ xảy ra khi X = 0 nên F(x) = P1 = 0,216
* Khi 0 < x = 2 biến cố (X < x) sẽ xảy ra khi X = 0 hoặc khi X = 1
Do đó: F(x) = P1 + P2 = 0,216 + 0,432 = 0,643
* Khi 2 < x = 3 ta có: F(x) = P1 + P2 + P3 = 0,216 + 0,432 + 0,288 = 0,936
* Khi x > 3 ta có: F(x) = P1 + P2 + P3 + P4 = 1
Vậy hàm phân phối xác suất có dạng:
 = \left \{ \begin{array}{c c} 0 & x = 0 \\ 0.216 & 0 < x = 1 \\ 0.648 & 1 < x = 2 \\ 0.936 & 2 < x = 3 \\ 1 & x > 3 \\ \end{array} \right.")
Đồ thị của F(x) được biểu diễn trên hình (3.1).

Như vậy đồ thị hàm phân phối xác suất của đại lượng ngẫu nhiên rời rạc có dạng bậc thang với số điểm gián đoạn chính bằng số giá trị có thể có của X.
Nếu X là đại lượng ngẫu nhiên liên tục thì hàm phân phối xác suất của nó liên tục và khả vi tại mọi điểm của X, do đó đồ thị của nó là đường cong liên tục.
b/ Các tính chất của hàm phân phối xác suất:
Tính chất 1: Hàm phân phối xác suất F(x) luôn nhận giá trị giữa 0 và 1: 0 ≤ F(x) ≤1.
Tính chất này được trực tiếp suy từ định nghĩa của hàm phân phối xác suất, vì nó là một xác suất nên: 0 ≤ F(x) ≤1
Tính chất 2: Hàm phân phối xác suất là hàm không giảm; tức là nếu x2 > x12 ) ≥ F(x1). thì F(x
Chứng minh: Giả sử x2 > x1 . Xét biến cố (X < x2) biến cố này có thể phân tích thành hai biến cố xung khắc là ( X < x1 ) và ( x1 = X < x2 ).
Theo định lý cộng xác suất ta có: P( X < x2 ) = P( X < x1 ) + P(x1 = X < x2 )
Hay F(x2 ) – F(x1 ) = P( x1 = X < x2 ) (3.2)
Song vế phải là một xác suất, nó luôn không âm do đó ta có: F(x2 ) – F(x1 ) ≥ 0
Vậy: F(x2 ) ≥ F(x1 ) ♦
Tính chất 3: Ta có biểu thức giới hạn sau: F(-∞) = 0; F(+∞) = 1.
Thật vậy: F(-∞) = P(X < -∞) = P(V) = 0; F(+∞) = P(X < +∞) = P(U) = 1
c) Các hệ quả:Từ các tính chất trên có thể suy ra một số hệ quả sau:
Hệ quả 1: Xác suất để đại lượng X nhận giá trị trong khoảng nửa kín bên trái [a, b) bằng hiệu các giá trị của hàm phân phối tại các nút: P(a = x < b) = F(b) – F(a).
Hệ quả này suy ra trực tiếp từ biểu thức (3.2) trong quá trình chứng minh tính chất 2.
Hệ quả 2: Xác suất để đại lượng ngẫu nhiên liên tục X nhận một giá trị xác định bằng 0: P(X=x) = 0.
Thật vậy, nếu đặt a = x, b = x + Δx, ta có: P(x = X < x + Δx) = F(x + Δx) – F(x).
Lấy giới hạn 2 vế khi Δx →0:
Vì X là đại lượng ngẫu nhiên liên tục do đó tại điểm x hàm phân phối xác suất cũng liên tục.
Vì vậy:
Do đó: P(X = x) = F(x) – F(x) = 0 ♦
Hệ quả 3: Đối với đại lượng ngẫu nhiên liên tục X ta có đẳng thức sau đây:
P(a ≤ X ≤ b) = P(a ≤ X < b) = P(a < X ≤ b) = P(a < X < b) = F(b) – F(a)
Chẳng hạn đẳng thức:
P(a ≤ X < b) = P(X = a) + P(a < X < b) = P(a < X < b)
Như vậy việc xét xác suất để đại lượng ngẫu nhiên liên tục X nhận một giá trị xác định là không có ý nghĩa, song việc tìm xác suất để nó nhận giá trị trong một khoảng lại rất có ý nghĩa.
d) Ý nghĩa của hàm phân phối xác suất:
Từ định nghĩa của hàm phân phối xác suất F(X) = P(X < x) ta thấy hàm phân phối xác suất phản ánh mức độ tập trung xác suất về phía bên trái của điểm x. Vì toàn bộ xác suất của đại lượng ngẫu nhiên bằng 1, do đó giá trị của hàm phân phối xác suất tại điểm x cho biết có bao nhiêu phần của một đơn vị xác suất phân phối trong khoảng (-∞, x)
3. Hàm mật độ xác suất:
a) Định nghĩa: Hàm mật độ xác suất của đại lượng ngẫu nhiên liên tục X ký hiệu là f(x) là đạo hàm bậc nhất của hàm phân phối xác suất của đại lượng ngẫu nhiên đó: f(x) = F’(x).
Từ định nghĩa trên ta thấy rằng hàm mật độ xác suất chỉ áp dụng được đối với đại lượng ngẫu nhiên liên tục vì chỉ trong trường hợp đó hàm phân phối xác suất F(x) mới liên tục và khả vi với mọi giá trị x.
b) Các tính chất của hàm mật độ xác suất:
Tính chất 1: Hàm mật độ xác suất luôn không âm: f(x) ≥ 0, với mọi x.
Chứng minh: Hàm phân phối xác suất F(x) là một hàm không giảm do đó đạo hàm của nó F’(x) = f(x) là một hàm không âm. Về mặt hình học điều đó có nghĩa là đồ thị của hàm f(x) không nằm thấp hơn trục Ox.
Tính chất 2: Xác suất để đại lượng ngẫu nhiên liên tục X nhận giá trị trong khoảng (a,b) bằng tích phân xác định của hàm mật độ xác suất trong khoảng đó:
Về mặt hình học, tính chất 2 được minh họa như sau:
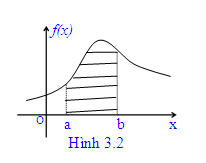
Xác suất để đại lượng ngẫu nhiên liên tục X nhận giá trị trong khoảng (a, b) bằng diện tích của miền giới hạn bởi trục Ox, đường cong f(x) và các đường thẳng x = a, x = b (miền gạch trên hình 3.2).
Tính chất 3: Hàm phân phối xác suất F(x) của đại lượng ngẫu nhiên liên tục X bằng tích phân suy rộng của hàm mật độ xác suất trong khoảng (-∞; x).
Công thức trên cho phép tìm hàm phân phối xác suất của đại lượng ngẫu nhiên liên tục khi biết hàm mật độ xác suất của nó.
Về mặt hình học, công thức trên cho thấy giá trị của hàm phân phối xác suất F(x) tại điểm a bằng diện tích giới hạn bởi trục Ox, đường cong f(x) và đường thẳng x = a (miền gạch trên hình 3.3).
Tính chất 4: tích phân suy rộng trong khoảng (-∞;∞) của hàm mật độ xác suất bằng 1
Thí dụ: Hàm phân phối xác suất của đại lượng ngẫu nhiên liên tục X có dạng:
a) Tìm hệ số a. b) Tìm hàm mật độ xác suất f(x). c) Tìm xác suất để đại lượng ngẫu nhiên X nhận giá trị trong khoảng (0,2; 0,8).
Giải
a. Vì hàm phân phối xác suất F(x) là liên tục nên:
Do đó: a = 1
b. Theo định nghĩa hàm mật độ. Ta có:
c. Theo tính chất hàm phân phối xác suất:
P(0.2 < x < 0.8) = F(0.8) – F(0.2) = 0.504
III . MỘT SỐ QUY LUẬT PHÂN PHỐI XÁC SUẤT RỜI RẠC
1. Quy luật nhị thức B(n, p)
a) Bài toán:
Từ tập hợp gồm N phần tử trong đó có M phần tử có tính chất B nào đó, còn N-M phần tử không có tính chất B, ta lấy ngẫu nhiên có hoàn lại n phần tử. Nếu lấy theo phương thức này thì n phép thử nói trên sẽ độc lập với nhau vì việc lấy được phần tử có tính chất B, hay không có tính chất B trong mỗi lần lấy không ảnh hưởng đến khả năng lấy được phần tử có tính chất B hay không có tính chất B ở các lần lấy khác. Trong mỗi lần lấy chỉ có 2 trường hợp đối lập xảy ra. Hoặc biến cố A xảy ra (lấy được phấn tử có tính chất B) hoặc biến cố A không xảy ra (lấy được phần tử không có tính chất B).
Xác suất cho biến cố A xảy ra trong mỗi phép thử đều bằng 

Gọi X là số lần biến cố A xảy ra trong n phép thử, thì X là đại lượng ngẫu nhiên rời rạc nhận các giá trị có thể có 0, 1, 2, …, n. Như đã chứng minh ở chương II, xác suất để X nhận các giá trị tương ứng được tính bằng công thức Bernoulli:
 = C_{n}^{x}{p^x}{(1-p)^{n-x}} (x = 0, 1, 2, ..., n)")
b) Định nghĩa: Đại lượng ngẫu nhiên rời rạc X nhận một trong các giá trị có thể có (x = 0, 1, …, n;) với các xác suất tương ứng được tính theo công thức (1) gọi là phân phối theo quy luật nhị thức với các tham số là n và p. Quy luật nhị thức được ký hiệu là B(n, p)
Nói cách khác, phân phối nhị thức gắn liền với việc lặp lại n lần một phép thử có hai sự kiện đối lập (thành công và thất bại; xảy ra và không xảy ra) với X là số lần thành công. Việc lặp lại ở đây có nghĩa là dãy phép thử được tiến hành trong cùng điều kiện và độc lập với nhau.
Như vậy bảng phân phối xác suất của đại lượng ngẫu nhiên X phân phối theo quy luật nhị thức có dạng:

Trong thực tế, nhiều khi ta cần tính xác suất để đại lượng ngẫu nhiên X phân phối theo quy luật nhị thức (ký hiệu là X ~ B(n, p)) nhận giá trị trong khoảng [x, x + h] (với h nguyên dương và h ≤ n – x). Khi đó ta có thể tính xác suất này theo công thức:
 = P_x + P_{x+1} + ... + P_{x+h}")
Trong đó: 
Thật vậy biến cố (x ≤ X ≤ x + h) có thể tách thành tổng của h +1 biến cố xung khắc từng đôi là (X = x), (X = x +1), …, (X = x + h); do đó áp dụng định lý cộng xác suất với các biến cố đó ta có:
 \\ = P(X = x) + P(X = x +1) + ... + P(X = x + h) \\ = P_{x} + P_{x+1} + ... + P_{x+h}")
Ví dụ 1:Gieo 4 hạt đậu, xác suất để 1 hạt cho cây ra hoa vàng là 0.75, ra hoa trắng là 0.25. Số cây đậu ra hoa vàng X có phân phối nhị thức B(4;0.75)
Ta có:
^{3}.0.25} & {0.75^4} \\ \end{array}")
Ví dụ 2: Một phân xưởng có 5 máy hoạt động độc lập, xác suất để trong một ngày mỗi máy bị hỏng đều bằng 0,1. Tìm xác suất để:
a) Trong một ngày có 2 máy hỏng.
b) Trong một ngày có không quá 2 máy hỏng.
Giải:
Nếu coi sự hoạt động của mỗi máy là một phép thử, ta có 5 phép thử độc lập. Trong mỗi phép thử chỉ có 2 trường hợp: hoặc máy hỏng hoặc không. Xác suất hỏng của mỗi máy đều bằng 0,1. Gọi X là số máy hỏng trong một ngày thì X phân phối theo quy luật nhị thức với các tham số n = 5, p = 0,1 (tức là X ~ B(5; 0,1)).
Do đó xác suất để trong một ngày có 2 máy hỏng là xác suất để X = 2. Theo công thức (3.2) ta có:
 = C_{5}^2(0,1)^2(0,9)^3 = 0,0729")
Xác suất để trong ngày có không quá 2 máy hỏng là xác suất để X nhận giá trị trong khoảng [0, 2]. Theo công thức (3.3) ta có:
 = P_{0} + P_{1} + P_{2}")
^0(0,9)^5 = 0,59049")
^1(0,9)^4 = 0,32805")
Vậy: P(0 ≤ X ≤ 2) = 0,59049 + 0,32805 + 0,0729 = 0,99144
Ví dụ 3: Một học sinh làm bài trắc nghiệm có 100 câu, mỗi câu gồm có 4 phương án lựa chọn, trong đó có 1 phương án trả lời đúng. Với một câu, nếu học sinh đó trả lời đúng thì được 1 điểm, ngược lại, sẽ không có điểm. Do học sinh đó lười học nên không nắm được bài, đã làm bài bằng cách chọn đại 1 phương án trả lời. Tìm xác suất để học sinh đó đạt được kết quả (đạt 50 điểm trở lên)
Học sinh thực hiện bài trắc nghiệm trên chính là đã thực hiện 100 phép thử Bernoulli, với xác suất thành công là 0.25. Gọi X là số điểm của học sinh đó thì X ~ B(100;0.25)
Tuy nhiên, ở đây ta không thể làm như ví dụ 2, vì xác suất của biến cố học sinh đạt kết quả tương đương với xác suất P( X ≥ 50). Vì việc liệt kê và tính từng trường hợp X = 50, 51, 52, …, 100 tốn rất nhiều thời gian.
Trong thực tế khi số phép thử n khá lớn, việc sử dụng các công thức (2) và (3) gặp nhiều khó khăn. Trong trường hợp này, người ta thường sử dụng các công thức gần đúng để tính toán.
Khi n khá lớn, xác suất p không quá gần 0 và không quá gần 1, ta có thể áp dụng công thức tích phân Laplace xấp xỉ như sau:
")
trong đó  = { \dfrac{1}{\sqrt{2.{\pi}}}} e^{-{ \dfrac{u^2}{2}}}")
Nhận xét:
1. Để tính giá trị của các hàm f(u), chúng ta có thể tra các giá trị hàm Laplace được tính sẵn ở các bảng phụ lục (thông thường các sách XSTK đều có bảng phụ lục này).
2. Dễ dàng nhận thấy hàm f(u) là hàm chẵn, do đó f(-u) = f(u), nên thông thường các bảng phụ lục chỉ ghi các giá trị ứng với u ≥ 0.
3. Hầu hết các bảng phụ lục chỉ tính f(u) với u ≤ 5. Với u > 5 thì hàm f(u) giảm rất chậm và nhận giá trị gần bằng 0. Do vậy ta có thể lấy f(u) = 0 (với mọi u > 5).
3. Từ công thức trên ta cũng có công thức xấp xỉ:
 = P(X=b) - P(X = a) \\ \approx {\varphi}({ \dfrac{b - np}{\sqrt{npq}}}) - {\varphi}({ \dfrac{a - np}{\sqrt{npq}}})")
trong đó  = { \dfrac{1}{\sqrt{2.{\pi}}}} \int_0^x e^{-{ \dfrac{u^2}{2}}} \, du")
Quay lại ví dụ 3 ở trên, ta sẽ áp dụng công thức tích phân Lapplace để tính xác suất học sinh đó đạt yêu cầu. Rõ ràng:
 = P(50 \le X \le 100) \\ \approx {\varphi} ( { \dfrac{100 - 100.(0.25)}{\sqrt{100.(0.25).(0.75)}}}) - {\varphi} ( { \dfrac{50 - 100.(0.25)}{\sqrt{18.75}}})")
Hay:
 \approx {\varphi}(17.32) - {\varphi}(5.77) \approx 0.5 - 0.5 \approx 0")
Khi xác suất p ≈ 0 (rất bé) ta sử dụng định lý sau:
Định lý Poisson:
Cho X ~ B(n;p).
Khi
")
Thì
 = { \dfrac{e^{- {\lambda}}{\lambda}^k}{k!}}")
Nghĩa là: khi n khá lớn và p khá nhỏ, n.p = const thì:
 \approx { \dfrac{e^{-{ \lambda}}.{ \lambda}^k}{k!}}")
Ví dụ: Xác suất gặp một thứ phẩm trong một lô hàng áo sơ mi cao cấp là 0,003. Tìm xác suất để gặp 8 thứ phẩm trong 1000 sản phẩm đó.
Giải: Do n = 1000 , p = 0,003 ≈ 0 → λ = np = 3
Gọi X là số thứ phẩm trong 1000 sản phẩm thì X ~ B(1000;0,003). Tuy nhiên do n lớn và p khá nhỏ nên ta áp dụng công thức tính xấp xỉ Poisson.
Ta có:
![P[X=8] \approx { \dfrac{e^{-3}.3^8}{8!}} \approx 0,0081](http://s3.wordpress.com/latex.php?latex=P%5BX%3D8%5D+%5Capprox+%7B+%5Cdfrac%7Be%5E%7B-3%7D.3%5E8%7D%7B8%21%7D%7D+%5Capprox+0%2C0081+&bg=ffffff&fg=333333&s=0 "P[X=8] \approx { \dfrac{e^{-3}.3^8}{8!}} \approx 0,0081")
Các ví dụ tương tự:
1. Một cuốn sách có 500 trang, mỗi trang có hơn 300 chữ. Biết cuốn sách đó có 300 chữ in sai. Mở ngẫu nhiên 1 trang. Tìm xác suất để trang đó có 3 chữ in sai. Đ/s: 0.0198
2. Trong 1 đợt xổ số, người ta phát hành 100.000 vé, trong đó có 10.000 vé trúng giải. Nếu 1 người mua 10 vé thì xác suất trúng ít nhất 1 vé là bao nhiêu? Đ/s: 0,76
3.Một trạm cho thuê xe du lịch có 3 chiếc xe. Hàng ngày, trạm phải nộp tiền trả góp 500.000đ cho 1 chiếc xe (bất kể xe đó có được thuê hay không). Mỗi chiếc được cho thuê với giá 1.500.000 đ /ngày.
Giả sử số xe được yêu cầu cho thuê của trạm trong 1 ngày là đại lượng ngẫu nhiên X có phân phối nhị thức B(3;0.8).
a.Tính số tiền trung bình trạm thu được trong 1 ngày.
b. Giải bài toán trên trong trường hợp trạm có 4 chiếc xe. Theo bạn, trạm nên có 3 hay 4 chiếc xe?
4. Xác suất để gặp 1 laptop bị lỗi là 0,005. Tìm xác suất để khi chọn ngẫu nhiên 1000 laptop ta gặp:
a. 10 máy bị lỗi. Đ/s: 0.018
b. Có không quá 5 máy bị lỗi Đ/s:0.61596
5. Trong một đợt thi nâng bậc thợ của ngành dệt, mỗi công nhân dự thi sẽ chọn ngẫu nhiên 1 trong 2 máy và với máy đã chọn dệt 100 sản phẩm.
Nếu trong 100 sản phẩm sản xuất ra có từ 75 sản phẩm loại 1 trở lên thì được nâng bậc.
Giả sử đối với công nhân A, xác suất để sản xuất được sản phẩm loại 1 đối với 2 máy lần lượt là 0.7 và 0.8.
Tính xác suất để công nhân được nâng bậc thợ. Đ/s: 0.5161
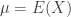 là giá trị kỳ vọng của biến ngẫu nhiên X, thì phương sai là
là giá trị kỳ vọng của biến ngẫu nhiên X, thì phương sai là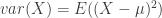 .
.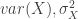 , hoặc đơn giản là
, hoặc đơn giản là 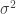 .
.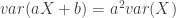 .
.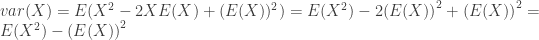 .
.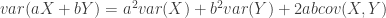 .
.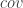 là hiệp phương sai, bằng 0 nếu X và Y là 2 biến ngẫu nhiên độc lập lẫn nhau.
là hiệp phương sai, bằng 0 nếu X và Y là 2 biến ngẫu nhiên độc lập lẫn nhau.![{var}\left[f(X)\right]\approx \left(f'({E}\left[X\right])\right)^2{var}\left[X\right]](https://s0.wp.com/latex.php?latex=%7Bvar%7D%5Cleft%5Bf%28X%29%5Cright%5D%5Capprox+%5Cleft%28f%27%28%7BE%7D%5Cleft%5BX%5Cright%5D%29%5Cright%29%5E2%7Bvar%7D%5Cleft%5BX%5Cright%5D+&bg=ffffff&fg=333333&s=0&c=20201002)
 khả vi bậc hai, trung bình và phương sai của X là hữu hạn (tức tồn tại).
khả vi bậc hai, trung bình và phương sai của X là hữu hạn (tức tồn tại). .
.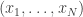 , được tính bởi:
, được tính bởi: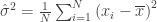 ,
,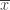 là số bình quân số học của mẫu.
là số bình quân số học của mẫu. là một ước lượng chệch (biased) của phương sai quần thể. Ước lượng sau là một ước lượng không chệch (unbiased) của phương sai quần thể:
là một ước lượng chệch (biased) của phương sai quần thể. Ước lượng sau là một ước lượng không chệch (unbiased) của phương sai quần thể: ,
,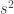 là một ước lượng không chệch của phương sai quần thể. Một ước lượng
là một ước lượng không chệch của phương sai quần thể. Một ước lượng 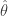 của tham số
của tham số  được gọi là ước lượng không chệch nếu
được gọi là ước lượng không chệch nếu 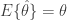 .
.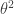 lần lượt là trung bình và phương sai của quần thể. Để chứng minh
lần lượt là trung bình và phương sai của quần thể. Để chứng minh 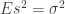 . Ta có:
. Ta có:
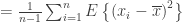

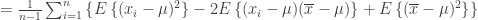

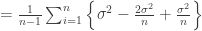

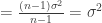
![E\left[ \sum_{i=1}^n {(x_i-\overline{x})^2}\right] =E\left[ \sum_{i=1}^n {x_i^2}\right] - nE[ \overline{x}^2]](https://s0.wp.com/latex.php?latex=E%5Cleft%5B+%5Csum_%7Bi%3D1%7D%5En+%7B%28x_i-%5Coverline%7Bx%7D%29%5E2%7D%5Cright%5D+%3DE%5Cleft%5B+%5Csum_%7Bi%3D1%7D%5En+%7Bx_i%5E2%7D%5Cright%5D+-+nE%5B+%5Coverline%7Bx%7D%5E2%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![=nE[x_i^2] - \frac{1}{n} E\left[\left(\sum_{i=1}^n x_i\right)^2\right]](https://s0.wp.com/latex.php?latex=%3DnE%5Bx_i%5E2%5D+-+%5Cfrac%7B1%7D%7Bn%7D+E%5Cleft%5B%5Cleft%28%5Csum_%7Bi%3D1%7D%5En+x_i%5Cright%29%5E2%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![=n({var}[x_i] + (E[x_i])^2) - \frac{1}{n} E\left[\left(\sum_{i=1}^n x_i\right)^2\right]](https://s0.wp.com/latex.php?latex=%3Dn%28%7Bvar%7D%5Bx_i%5D+%2B+%28E%5Bx_i%5D%29%5E2%29+-+%5Cfrac%7B1%7D%7Bn%7D+E%5Cleft%5B%5Cleft%28%5Csum_%7Bi%3D1%7D%5En+x_i%5Cright%29%5E2%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![=n\sigma^2 + \frac{1}{n}(nE[x_i])^2 - \frac{1}{n}E\left[\left(\sum_{i=1}^n x_i\right)^2\right]](https://s0.wp.com/latex.php?latex=%3Dn%5Csigma%5E2+%2B+%5Cfrac%7B1%7D%7Bn%7D%28nE%5Bx_i%5D%29%5E2+-+%5Cfrac%7B1%7D%7Bn%7DE%5Cleft%5B%5Cleft%28%5Csum_%7Bi%3D1%7D%5En+x_i%5Cright%29%5E2%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![=n\sigma^2 - \frac{1}{n}\left( E\left[\left(\sum_{i=1}^n x_i\right)^2\right] - \left(E\left[\sum_{i=1}^n x_i\right]\right)^2\right)](https://s0.wp.com/latex.php?latex=%3Dn%5Csigma%5E2+-+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%28+E%5Cleft%5B%5Cleft%28%5Csum_%7Bi%3D1%7D%5En+x_i%5Cright%29%5E2%5Cright%5D+-+%5Cleft%28E%5Cleft%5B%5Csum_%7Bi%3D1%7D%5En+x_i%5Cright%5D%5Cright%29%5E2%5Cright%29&bg=ffffff&fg=333333&s=0&c=20201002)
![=n\sigma^2 - \frac{1}{n}\left({var}\left[\sum_{i=1}^n x_i\right]\right) =n\sigma^2 - \frac{1}{n}(n\sigma^2) =(n-1)\sigma^2](https://s0.wp.com/latex.php?latex=%3Dn%5Csigma%5E2+-+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%28%7Bvar%7D%5Cleft%5B%5Csum_%7Bi%3D1%7D%5En+x_i%5Cright%5D%5Cright%29+%3Dn%5Csigma%5E2+-+%5Cfrac%7B1%7D%7Bn%7D%28n%5Csigma%5E2%29+%3D%28n-1%29%5Csigma%5E2+&bg=ffffff&fg=333333&s=0&c=20201002) .
. là một véc tơ ngẫu nhiên, xác định trên
là một véc tơ ngẫu nhiên, xác định trên 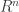 , thì phương sai của
, thì phương sai của ![E[(X-\mu )(X-\mu )^{T}]](https://s0.wp.com/latex.php?latex=E%5B%28X-%5Cmu+%29%28X-%5Cmu+%29%5E%7BT%7D%5D&bg=ffffff&fg=333333&s=0&c=20201002)
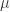 =
= 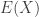 và
và 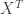 là ma trận chuyển vị của
là ma trận chuyển vị của 
{kind=link}
{kind=link}